Googleの1500万冊のうち、450万冊はダブり
9月2日に、kikoriさんから、
(仮に)国会図書館に800万冊、ICU図書館に65万冊の本があっても、865万種類の本があるわけじゃなくてある程度というか何万冊もダブりがあるわけですよね?となると、無駄なダブりを防ぐ為に情報交換が必要なんじゃないかと思うのですが、その辺は何か話し合いがあるのでしょうか?
というコメントをもらった。
だから、ちょっとの間、「ダブり」について考える。
昨日は、リストアップされた本を集めて、出荷するまでを見た。そのつながりで考えれば、今日は、「リスト作り」の部分を見てみることになる。
「ダブり」と言えば、この論文。
もう1年も前のものだけど、「世の中には、こんなことまで調べてる人がいるんだ〜」と感動する一品。
まず、この調査は、
The analysis that follows is based on a copy of WorldCat dating from January 2005, containing nearly 55 million records.
ということで、WorldCatと呼ばれる「世界版NACSIS Webcat」のデータを使ったよ、ということ。書かれた当時(2005年1月)では、全部で5,500万冊の登録だったって言ってる。(今は6,800万冊くらいまで成長してるけどね。)
まず、Googleプロジェクトの総数確認。
As of January 2005, the Google 5 have set more than 18 million holdings
「Google 5」ってのは、Harvard大学図書館、Stanford大学図書館、Michigan大学図書館、Oxford大学図書館、New York公立図書館の総称ね。(かっこいいね。)そんで、この「グーグル・ファイブ」が持っている本というのは、全部で1,800万冊になるらしい。
当然そこには、ダブりが存在するわけだから、各図書館の「ダブり」を取り除いてみると、
once duplicate holdings across the five institutions are removed, (it) is ... 10.5 million unique books
ということで、1,050万冊になるそうだ。
次に、その1,050万冊について、詳しく見ていて、
Figure 2: Google 5 Holdings Overlap
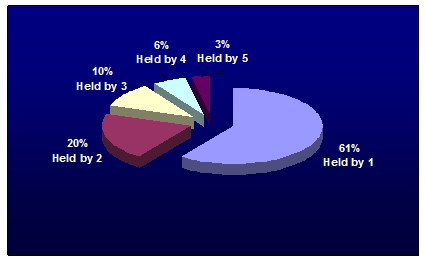
グラフの見方は、「1,050万冊のうち、61%にあたる630万冊は、グーグル・ファイブのどれかひとつの図書館だけにしか所蔵されてなくて(Held by 1)、20%はどれかふたつの図書館に所蔵されている(Held by 2)」って感じ。
「Held by 5」という「5つの図書館が、みんな持ってる本」ってのは、たったの31.5万冊(3%)だけだって。「グーグル・ファイブ」総なめってことだから、かなりの名誉だね。
というわけで、「ダブり率」というのがあるとすると、「Held by 1」以外のことを指すはずだから、おおよそ40%(≒100-61)ってことになる。じゃあ、この40%の「ダブり率」ってのは、大きいのかな、小さいのかな?
overlap across the Google 5 collections can be considered quite small.
(中略)
Of course, interpretation of this result is not straightforward, and must be considered carefully before any definitive conclusions are drawn, but at least on the surface, it does lend credence to the view that research library collections are less "vanilla" than commonly supposed.
ということで、「いや、こんだけしかダブってないってのは、少ないって言えるよ。図書館なんてみんな似たり寄ったりなんじゃないの、なんて思ってたけど、意外にそうじゃなかったって言えるんじゃないかな」という結論。
まぁ、多いか少ないか、このさいどうでもいいか。(いたって、主観の問題だしね。)
とにかく、Googleプロジェクトでスキャン予定の1500万冊のうち、約450万冊はダブってる状態。
じゃ、そのダブりは放置?それとも、何か対策を打つ?
というわけで明日は、「ダブり」の事情をさらに探ってみる。